UniverSat: Resolution- and Modality-Agnostic Transformers for Earth Observation
arXiv preprint, 2026


UniverSat
A resolution- and modality-agnostic transformer backbone for Earth Observation: one set of weights for any sensor, any spatial/spectral/temporal resolution and any scale.
*Equal contribution · LASTIG, Univ Gustave Eiffel | IGN | ENSG | CNES | LIGM, ENPC, IPP | EFEO
One Model. Any Sensor. Any Resolution.
ViTs assume a fixed input format. Earth Observation doesn't play by that rule:
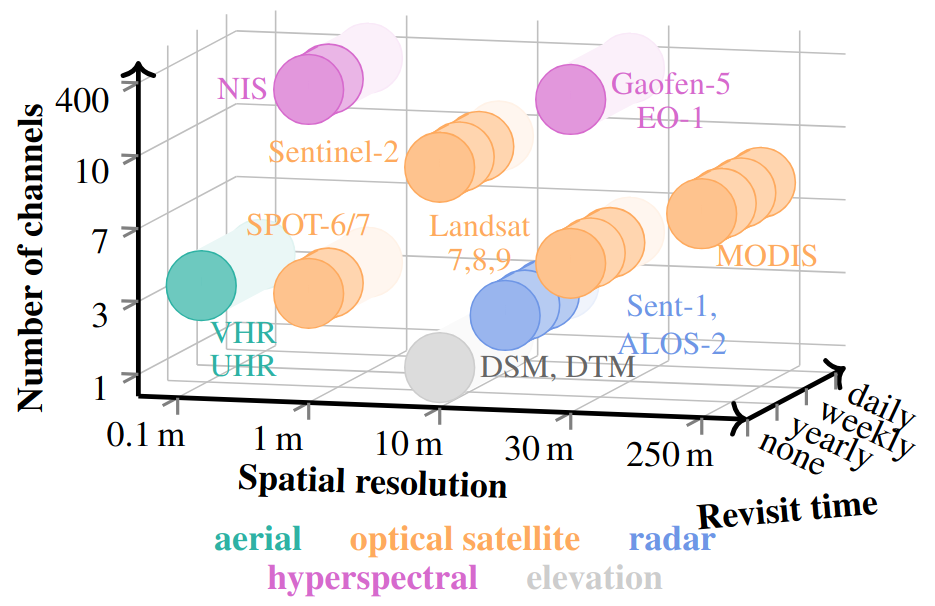
- Modalities — optical, radar, hyperspectral, elevation
- Spatial resolution — centimetres to hundreds of metres
- Image size — tiny patches to multi-kilometre tiles, no two images share the same shape
- Temporal depth — single snapshot up to 150+ revisits
- Spectral width — from one band to 396 channels
UniverSat handles all of this with a single set of weights — no resampling, no channel selection, no per-sensor encoder. It is a ViT-style backbone built around a Universal Patch Encoder (UPE) that maps patches of arbitrary spatial, spectral, and temporal shape into a shared embedding space. One model is trained jointly on 13 sensors from 7 datasets, generalises to unseen sensors within this gamut without input resampling, and stays competitive on standard benchmarks.
Use UniverSat in three lines.
UniverSat is designed to be a drop-in backbone for any EO pipeline. Load the pretrained weights in one line via torch.hub — no clone, no config — feed a dict of whichever sensors you have, and read out dense embeddings at any output resolution. No modality-specific preprocessing, no channel filtering, no input resampling.
1 Load a pretrained model
The model is published on the Hugging Face Hub with PyTorchModelHubMixin. The simplest path is Torch Hub — no local checkout needed:
import torch model = torch.hub.load('gastruc/UniverSat', 'from_pretrained').eval()
Or, equivalently, with the repo on your path and huggingface_hub installed:
from hubconf import UniverSat model = UniverSat.from_pretrained('g-astruc/UniverSat').eval()
Loading requires huggingface_hub (and safetensors). The released checkpoint is a Base UniverSat (~201 M params).
2 Encode any sensor combination
# Snapshot modalities: (B, C, H, W). Time series: (B, T, C, H, W) + <mod>_dates. data = { 'spot': torch.randn(2, 3, 360, 360), # 1 m VHR, RGB snapshot 's2': torch.randn(2, 20, 10, 36, 36), # 10 m Sentinel-2 time series 's2_dates': torch.randint(0, 365, (2, 20)), 's1': torch.randn(2, 12, 3, 36, 36), # 10 m Sentinel-1 (SAR) time series 's1_dates': torch.randint(0, 365, (2, 12)), 'dsm': torch.randn(2, 1, 12, 12), # 30 m elevation snapshot } features, _ = model.encode(data, patch_size=40, output_grid=36) # -> (2, 1296, 768): a 36x36 dense feature grid (register tokens stripped for you)
model.encode(...) looks up per-modality wavelengths, physical resolution, and sub-patch factors automatically from a built-in registry — s2, s1, spot, aerial, naip, l7/l8, modis, alos, enmap, dsm, neon, hls, and more.
3 Control input and output resolutions
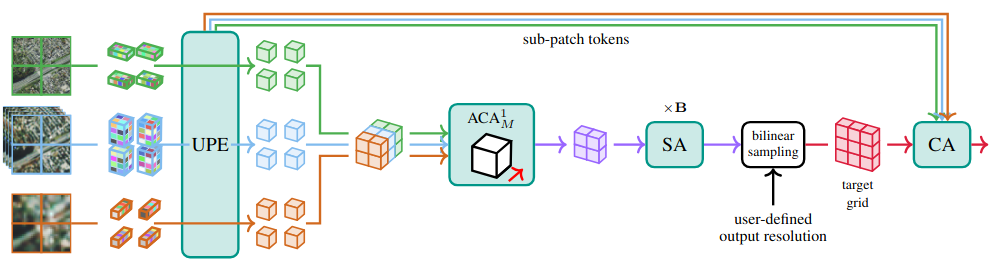
With UniverSat, the output resolution is decoupled from the input patch size.
First, choose the patch_size used to partition the input data. Smaller patches better capture local, fine-grained processes, while larger patches are more efficient.
Then, choose the output_grid, i.e. the number of output tokens. The model returns a tensor of shape D × output_grid × output_grid (each token then covers tile_extent / G on the ground). Same model, same inputs — only the requested grid changes.
# Same model, same inputs — only the requested output grid changes. patch, _ = model.encode(data, patch_size=40, output_grid=9) # 9x9 patch-level dense, _ = model.encode(data, patch_size=40, output_grid=36) # 36x36 dense highres, _ = model.encode(data, patch_size=40, output_grid=180) # 180x180 high-res
Under the hood: the patch-level transformer runs over a coarse spatial grid, then a sub-patch skip cross-attention recovers fine spatial detail at the requested grid — one bilinear resample plus one CA pass.
See our demo notebook.
⚠️ Note: small input patches or very fine output grids can significantly increase memory usage.
Frozen-backbone friendly
Strong results with linear probes and just 9K probe parameters — perfect for low-label regimes.
Lightweight integrations
The forward pass returns standard dense features — plug them into any segmentation / classification head you already use.
Reference recipes
The GitHub repo ships with fine-tuning, kNN, and linear-probe scripts for GeoBench, PangaeaBench, and SpectralEarth.
One model for all your EO needs.
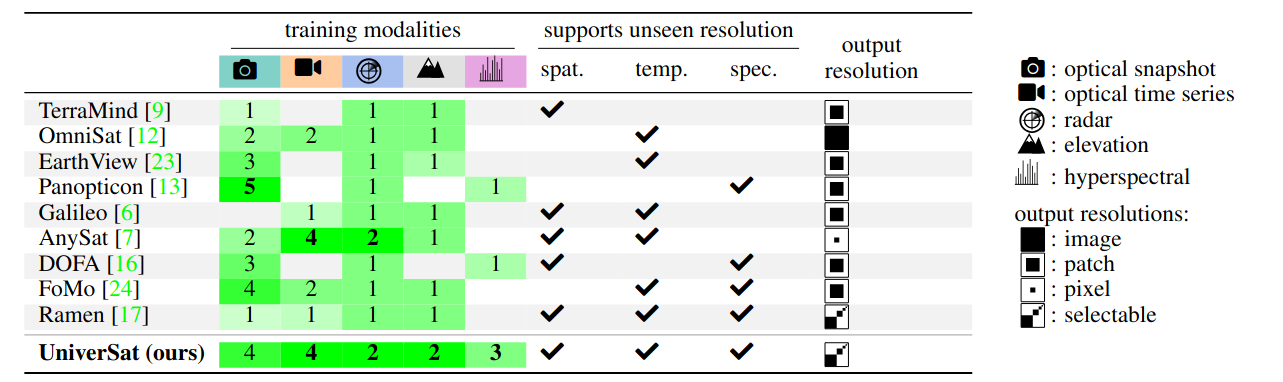
Integrated into a transformer that operates over spatialized tokens, the Universal Patch Encoder gives UniverSat three key advantages over rigid ViT-style EO foundation models:
Sensor-agnostic
A single set of weights processes any modality combination and arbitrary resolutions — no resampling, no channel filtering.
Resolution-flexible
The output spatial resolution is specified at inference time, decoupled from the input patch size.
Granular
A sub-patch skip connection preserves fine spatial details well beyond the patch-level embedding.
The Universal Patch Encoder
Different sensors yield patches of fundamentally different shapes: C channels × T timestamps × H × W pixels. Naively projecting every shape with an MLP is impractical; applying full self-attention over all atomic tokens is prohibitive.
The UPE instead lifts each scalar into a learnable embedding using Fourier features, and progressively collapses the spectral, temporal, spatial-within-patch, and sub-patch axes one at a time using linear-complexity Axial Cross-Attention. Each axis receives dedicated positional encodings (wavelength, polarization, time-of-year, etc.), so the encoder is intrinsically aware of what each input is — not just where it sits.
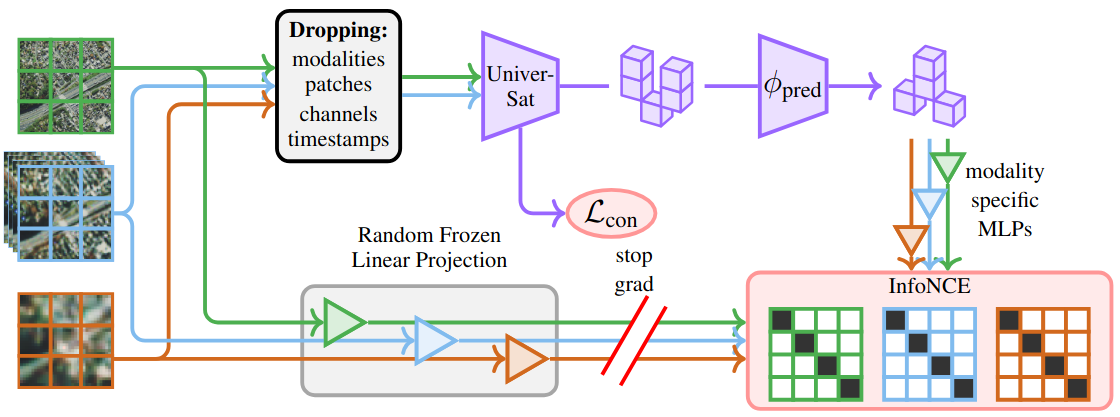
Self-supervised on 13 sensors at once
UniverSat is trained with a self-supervised objective that combines (i) cross-modal contrastive learning at the patch level and (ii) latent multimodal masked modeling (LM₃), an extension of latent masked image modeling to heterogeneous, multimodal, multitemporal EO data.
Aggressive input dropping — modalities, patches, channels, and timestamps — removes ≈90% of input atoms at training time, drastically improving robustness across scales and sensor configurations.
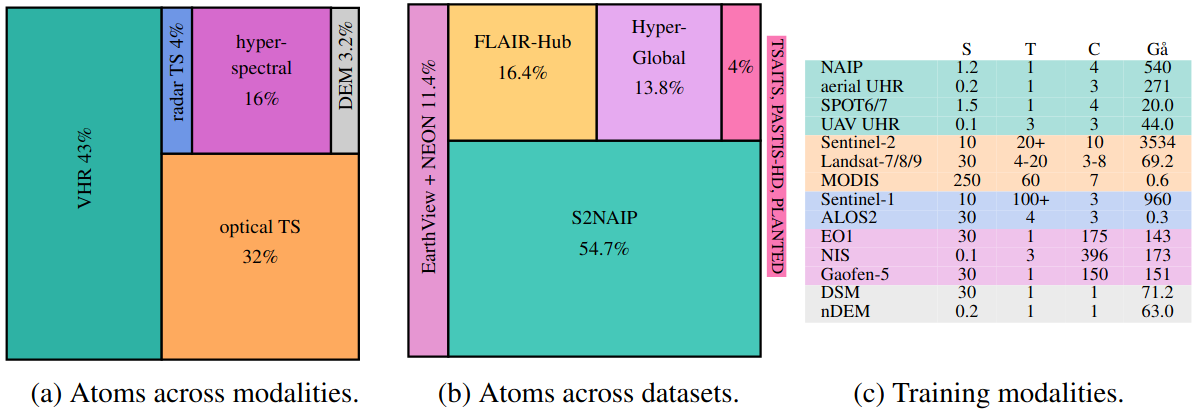
Competitive — and broader — than the state of the art
Despite its flexibility and ability to ingest unseen sensor configurations, UniverSat remains highly competitive on standard benchmarks. We evaluate on 16 datasets spanning GeoBench, PangaeaBench, and the hyperspectral SpectralEarth benchmark using strict probing protocols (kNN and linear probing).
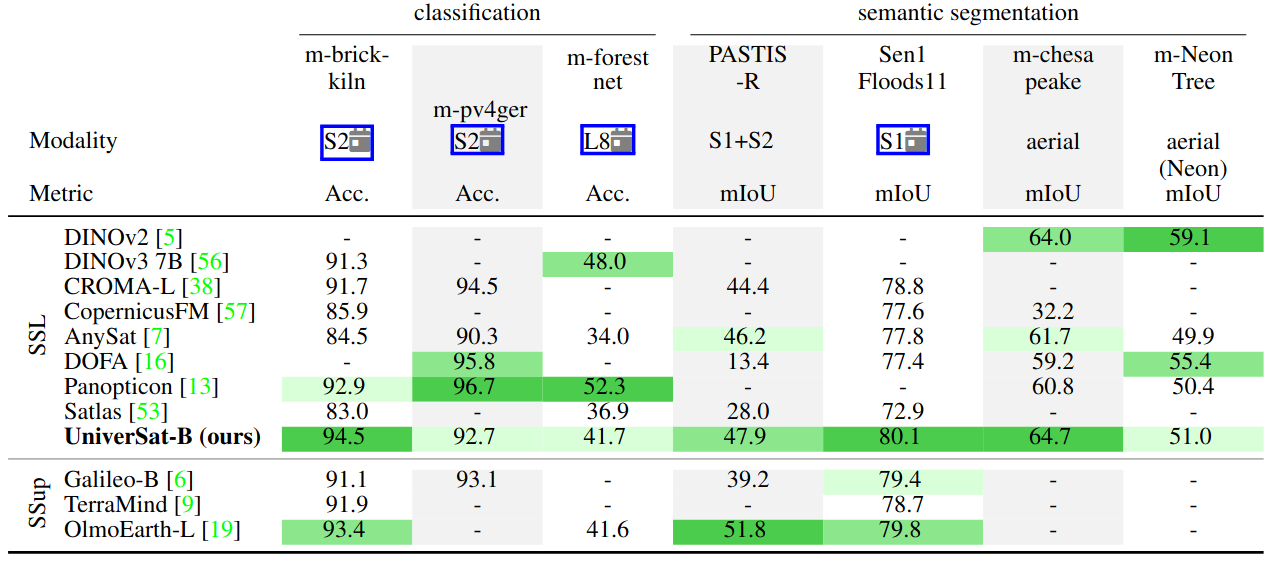
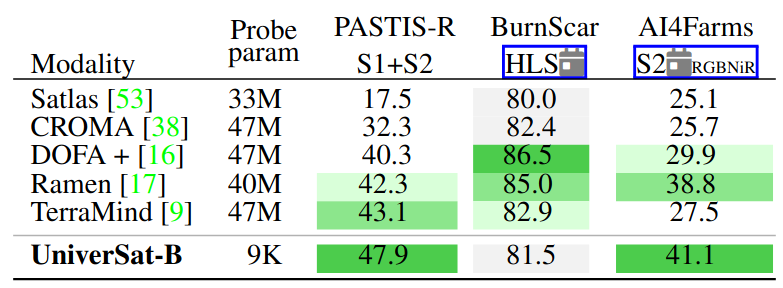
PangaeaBench — linear probes match heavyweight decoders
On PangaeaBench, competing models attach 33M–47M-parameter UperNet decoders. UniverSat uses a single 9K-parameter linear probe on top of its dense embeddings — 3700–5000× fewer supervised parameters — and still reaches or exceeds the state of the art on PASTIS-R and AI4Farms, including configurations the model never saw at pretraining (mono-temporal Sentinel inputs, the synthetic HLS sensor).
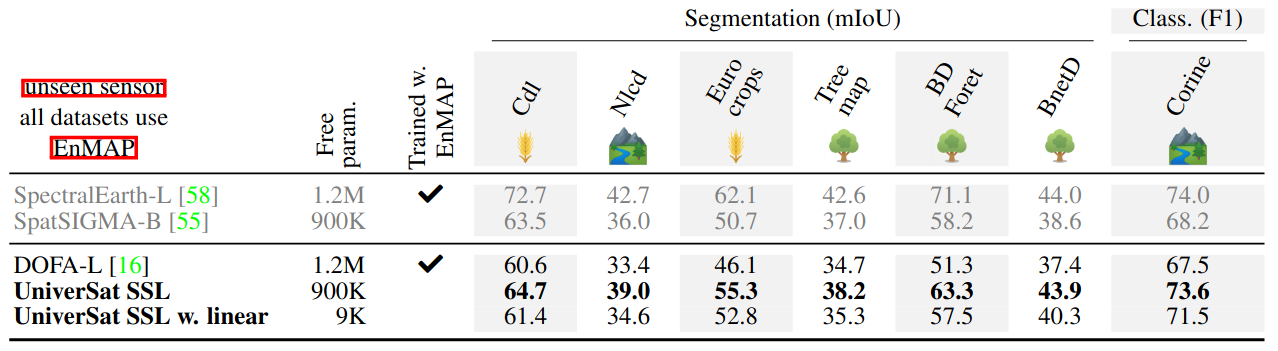
Hyperspectral — competitive without ever seeing EnMAP
On the SpectralEarth benchmark (EnMAP, up to 500 bands), UniverSat outperforms DOFA-L — a foundation model trained on EnMAP — across every task, and approaches SpectralEarth-L, a model specifically designed for EnMAP and trained with self-supervision on the evaluation data itself. UniverSat was never trained on EnMAP.
Sharper, modality-agnostic spatial features
Thanks to its controllable output resolution and sub-patch skip connection, UniverSat produces higher-resolution embeddings that preserve fine spatial structures — field boundaries, roads, parcel edges — compared to fixed-resolution backbones. PCA projections on a PASTIS test tile reveal markedly less positional collapse than other multimodal foundation models.

What this paper delivers
- A unified ViT-like architecture for EO that processes heterogeneous sensors without modality-specific projectors or preprocessing.
- A multimodal self-supervised training framework combining cross-modal contrastive and latent multimodal masked modeling (LM₃).
- Competitive performance across 16 datasets — from VHR RGB to radar time series to 500-band hyperspectral imagery.
- Demonstrated generalisation to unseen sensors and modality combinations without input resampling.
Cite Our Work
@article{perron2026universat,
title = {UniverSat: Resolution- and Modality-Agnostic Transformers for Earth Observation},
author = {Perron, Yohann and Astruc, Guillaume and Gonthier, Nicolas
and Mallet, Clement and Landrieu, Loic},
journal = {arXiv preprint},
year = {2026}
}