UNIGEOCLIP: Unified Geospatial Contrastive Learning
EarthVision (CVPRW) 2026
UniGeoCLIP
Unified Geospatial Contrastive Learning
LASTIG, Univ Gustave Eiffel | IGN | ENSG | CNES | LIGM, Ecole des Ponts ParisTech | Google Switzerland
Five Modalities, One Unified Space
Geospatial understanding requires reasoning across fundamentally different kinds of data -- a satellite view from above, a street photo at ground level, a 3D elevation map, a text description of a neighborhood, and a pair of GPS coordinates. These modalities are complementary: each one captures something the others miss.
UniGeoCLIP is the first contrastive framework to jointly align all five modalities into a single unified embedding space, enabling seamless retrieval and reasoning across any combination of inputs, without relying on a privileged "pivot" modality.
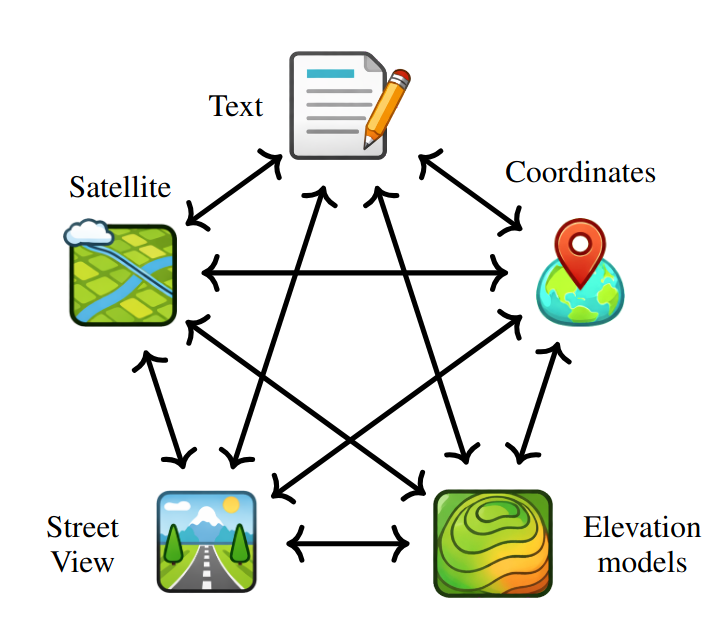
All-to-All, Not Pivot-Centric
Prior multimodal contrastive models like ImageBind and UniBind rely on a central pivot. This creates an asymmetry and forces cross-modal retrieval between two non-image inputs to pass through the pivot.
UniGeoCLIP takes a fundamentally different approach: every modality is directly contrasted against every other modality via a multi-way InfoNCE objective summed over all ordered modality pairs. Text, DSM, aerial imagery, street views and coordinates are all primary citizens in the same latent space.
All-to-All Alignment
Contrastive loss over all M^2 ordered pairs.
Modality-Invariant Geography
Same location, any modality -> nearby embeddings.
Zero-Shot Cross-Modal Retrieval
Query with one modality, retrieve another without task-specific heads.
Co-located Five-Modality Data
Training spans continental USA metropolitan centers with uniform spatial coverage using ~800k S2 cells at level L=16. To prevent temporal leakage, all data from 2023 is held out for evaluation.

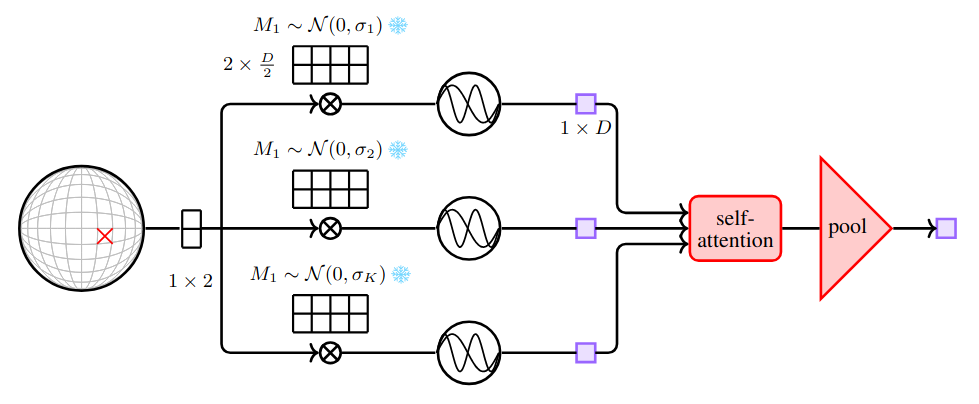
A Scaled Coordinate Encoder That Actually Understands Space
Raw latitude/longitude coordinates contain rich geographic structure — but only if the encoder can capture dependencies across multiple spatial scales simultaneously. Prior approaches such as GeoCLIP process each Fourier frequency independently through a separate MLP before averaging, leaving cross-scale interactions unexploited and tying parameter count to the number of frequencies.
Our Scaled Latitude–Longitude Encoder rethinks this design. Each frequency projection is treated as a token and processed jointly through self-attention blocks, letting every scale communicate with every other. Register tokens act as persistent memory banks, further increasing representational capacity. Crucially, the parameter count is now independent of the number of frequency scales — making the encoder both more expressive and more efficient to scale.
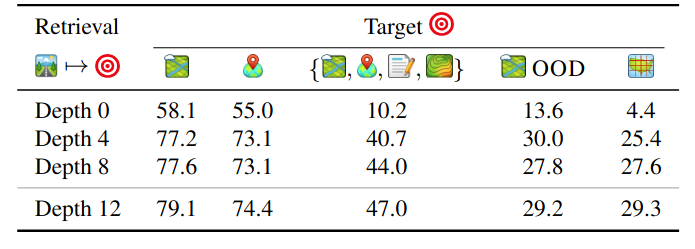
The depth of the encoder matters significantly. At depth 0, the model reduces to plain fixed Fourier features with no learned interactions. As self-attention blocks are added, all retrieval metrics improve consistently, and the gains extend beyond coordinate retrieval to aerial localization and multimodal ensembling.
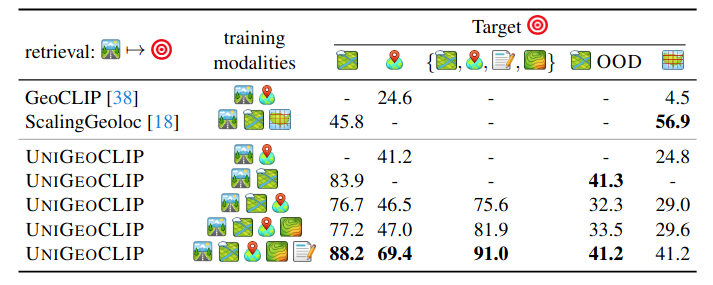
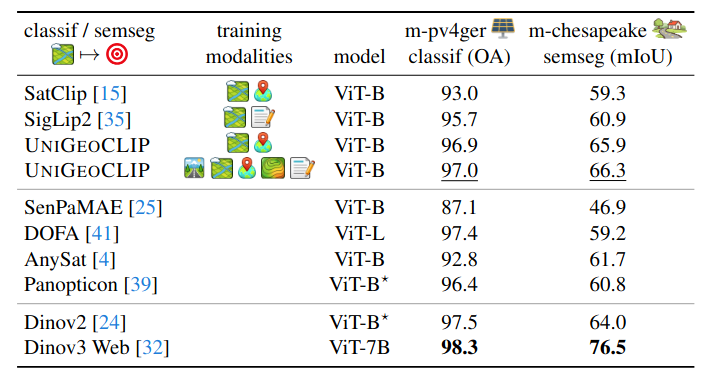
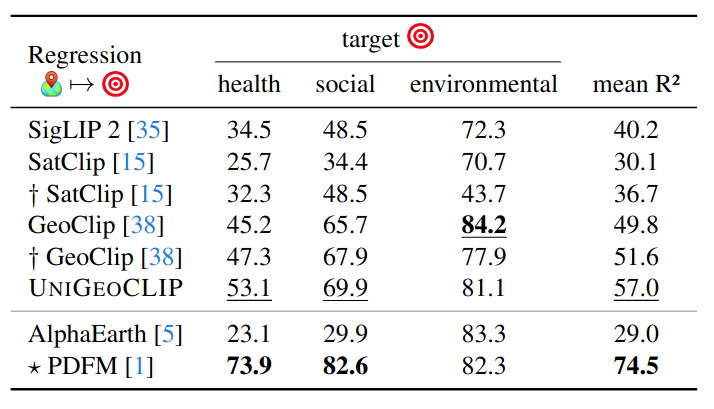
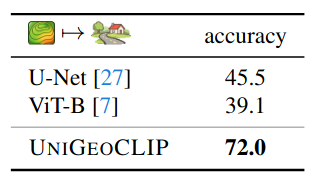
State-of-the-Art Across Every Geospatial Task
We evaluate UniGeoCLIP on cross-modal street-view retrieval, satellite image encoding (solar panels, land cover), spatial coordinate regression (health/socio-economic/environment indicators), and DSM understanding.
SV -> Aerial (full model)
m-pv4ger solar panels
27 regression tasks
DSM land-cover (MDAS)
Semantically Structured Geographic Representations
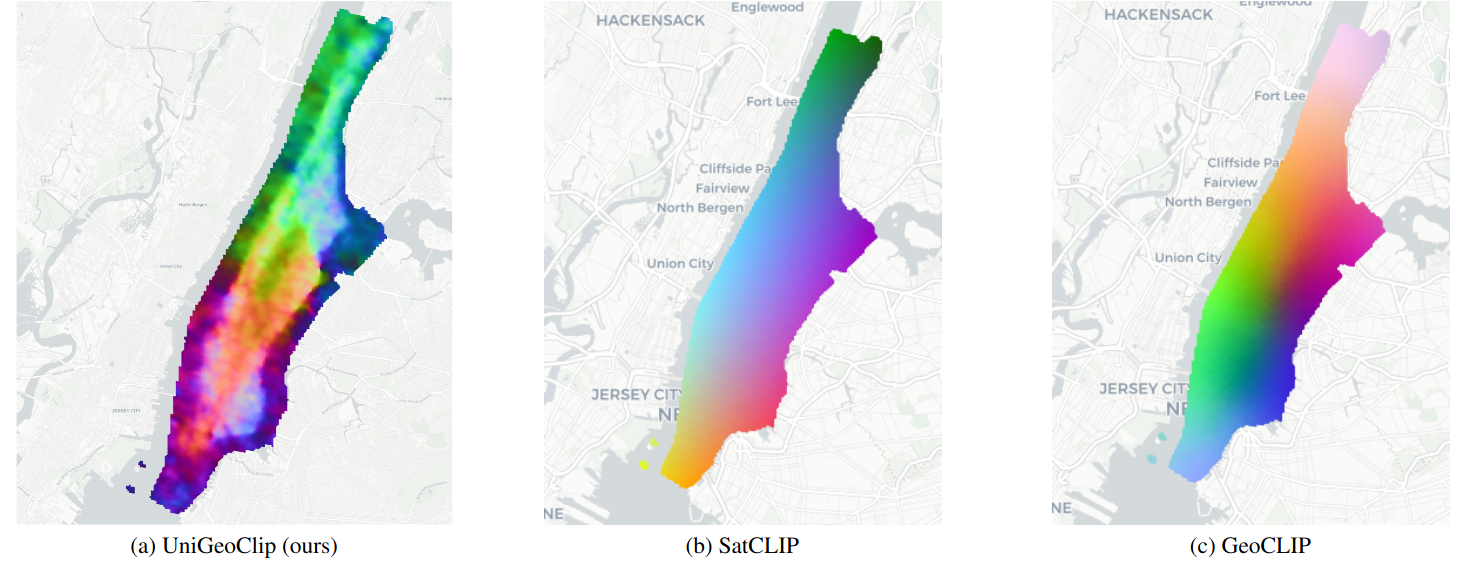
The learned embedding space is not only accurate; it is also structured. When applying PCA over a dense grid in Manhattan, UniGeoCLIP produces spatial patterns reflecting underlying urban structure (for example, Central Park stands out).
In contrast, SatCLIP and GeoCLIP exhibit smoother, predominantly position-driven gradients. UniGeoCLIP learns what a place means, not just where it is.
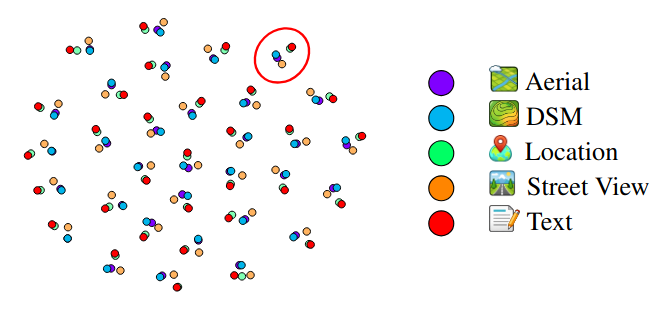
The t-SNE visualization (Figure 6) qualitatively checks whether embeddings from the five modalities truly co-localize for the same geographic location in the shared space. Clusters of points correspond to the exact same location.
Trained in the USA. Works in Amsterdam.
UniGeoCLIP is trained exclusively on US metropolitan areas, yet achieves 41.2% Acc@100m on an out-of-distribution Amsterdam evaluation set under a substantial domain shift, using an image-to-image retrieval protocol. The paper reports consistent performance trends: adding modalities helps, and multimodal ensembling remains beneficial. Note that for the location/coordinate encoder regression benchmark, the paper evaluates only on locations that overlap with the training area.
Cite Our Work
@inproceedings{astruc2026unigeoclip,
title = {UniGeoCLIP: Unified Geospatial Contrastive Learning},
author = {Astruc, Guillaume and Trulls, Eduard and Hosang, Jan
and Landrieu, Lo{\"i}c and Sarlin, Paul-Edouard},
booktitle = {EarthVision Workshop, CVPR},
year = {2026}
}