OmniSat: Self-Supervised Modality Fusion for Earth Observation
Published in ECCV, 2024
OmniSat: Self-Supervised Modality Fusion for Earth Observation
Description
Abstract
We introduce OmniSat, a novel architecture that exploits the spatial alignment between multiple EO modalities to learn expressive multimodal representations without labels. We demonstrate the advantages of combining modalities of different natures across three downstream tasks (forestry, land cover classification, and crop mapping), and propose two augmented datasets with new modalities: PASTIS-HD and TreeSatAI-TS.
Datasets
| Dataset name | Modalities | Labels | Link |
|---|---|---|---|
| PASTIS-HD | SPOT 6-7 (1m) + S1/S2 (30-140 / year) | Crop mapping (0.2m) | huggingface or zenodo |
| TreeSatAI-TS | Aerial (0.2m) + S1/S2 (10-70 / year) | Forestry (60m) | huggingface |
| FLAIR | aerial (0.2m) + S2 (20-114 / year) | Land cover (0.2m) | huggingface |
Results
We perform experiments with 100% and 10-20% of labels. See below, the F1 Score results on 100% of the training data with all modalities available:
| F1 Score | UT&T | Scale-MAE | OmniSat (no pretraining) | OmniSat (with pretraining) |
|---|---|---|---|---|
| PASTIS-HD | 53.5 | 42.2 | 59.1 | 69.9 |
| TreeSatAI-TS | 56.7 | 60.4 | 73.3 | 74.2 |
| FLAIR | 48.8 | 70.0 | 70.0 | 73.4 |
OmniSat also improves performance even when only one modality is available for inference. F1 Score results on 100% of the training data with only S2 data available:
| F1 Score | UT&T | Scale-MAE | OmniSat (no pretraining) | OmniSat (with pretraining) |
|---|---|---|---|---|
| PASTIS-HD | 61.3 | 46.1 | 60.1 | 70.8 |
| TreeSatAI-TS | 57.0 | 31.5 | 49.7 | 62.9 |
| FLAIR | 62.0 | 61.0 | 65.4 | 65.4 |
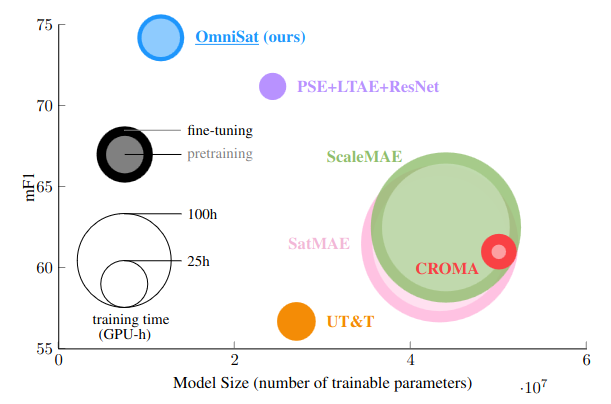
Efficiency
We report the best performance of different models between TreeSatAI and TreeSatAI-TS, with pre-training and fine-tuning using 100% of labels. The area of the markers is proportional to the training time, broken down in pre-training and fine-tuning when applicable